

Aurora for MySQL에서 CDC를 준비하는 과정

CDC란?
- CDC(Change Data Capture)는 데이터베이스의 변경 사항을 식별, 추적, 캡처하는 프로세스입니다. 이 방법은 일반적으로 데이터 웨어하우징, 데이터 동기화, 데이터 통합, 및 실시간 분석과 같은 분야에서 사용됩니다. CDC를 사용해야 하는 주요 이유와 이를 통해 수행할 수 있는 작업들을 살펴보도록 하겠습니다.

AWS에서 물리적인 CDC 구현 예시
CDC를 사용해야 하는 이유
- 성능 향상: CDC를 사용하면 전체 데이터 집합을 처리하는 대신 변경된 데이터만 처리합니다. 이로 인해 시스템 부하가 줄어들고 처리 시간이 단축됩니다.
- 데이터 실시간성: 데이터베이스의 변경 사항을 실시간으로 캡처하여 다른 시스템과 실시간으로 동기화 할 수 있습니다. 이로써, 사용자는 항상 최신 데이터에 액세스할 수 있습니다.
- 데이터 통합: 여러 시스템에서 데이터를 수집하고 통합하는데 CDC를 사용할 수 있습니다. 이를 통해 일관성 있는 뷰를 제공하고 데이터 품질을 향상시킬 수 있습니다.
- 데이터 복구: 데이터베이스에 문제가 발생한 경우, CDC 기록을 사용하여 특정 시점으로 롤백하거나 데이터를 복구하는데 도움이 될 수 있습니다.
- 분석과 보고: 데이터 웨어하우스에 데이터를 로드하는데 CDC를 사용하여 최신 데이터를 기반으로 분석하고 보고서를 생성할 수 있습니다.
- 이벤트 드리븐 아키텍처: 데이터 변경을 이벤트로 취급하고 이를 이용하여 마이크로서비스, 알림, 또는 다른 응용 프로그램과 연동할 수 있습니다.
CDC를 통해 수행할 수 있는 것들
- 데이터 동기화: 여러 데이터베이스 또는 시스템 간에 데이터를 실시간으로 동기화합니다.
- 데이터 마이그레이션: 데이터베이스 또는 플랫폼 간의 데이터 이동을 수행합니다.
- 실시간 분석: 실시간 데이터를 분석하여 즉각적인 인사이트를 제공합니다.
- 이벤트 처리: 데이터베이스 변경 사항을 이벤트로 변환하여 이를 이용해 이벤트 기반의 아키텍처를 구축합니다. 이를 통해 특정 데이터 변경에 대응하여 알림, 워크플로우 처리, 또는 기타 자동화된 작업을 실행할 수 있습니다.
- 데이터 감사 및 컴플라이언스: 데이터 변경 기록을 추적하여 누가 어떤 데이터를 변경했는지에 대한 감사 추적을 제공합니다. 이는 또한 컴플라이언스 요구 사항을 충족하는데 도움이 됩니다.
- 캐싱 시스템 최적화: CDC를 사용하여 데이터베이스의 변경을 감지하고 이를 기반으로 캐시를 업데이트합니다. 이로 인해 캐싱 시스템이 항상 최신 상태를 유지하면서 성능을 향상시킬 수 있습니다.
- 비즈니스 인텔리전스(BI) 강화: CDC를 이용하여 데이터 웨어하우스에 실시간 데이터를 공급하고, 이를 기반으로 비즈니스 인텔리전스 도구를 사용하여 고급 분석, 시각화, 그리고 의사결정을 지원합니다.
- 오류 복구: 데이터 변경 이력을 사용하여 시스템 상태를 이전 상태로 되돌리거나, 특정 시점의 상태로 복구하는데 사용할 수 있습니다.
- 서비스 간 데이터 전파: 마이크로서비스 아키텍처에서 서비스 간에 데이터 변경 사항을 전파하여, 각 서비스가 일관성을 유지하고 서로 동기화를 유지할 수 있게 합니다.
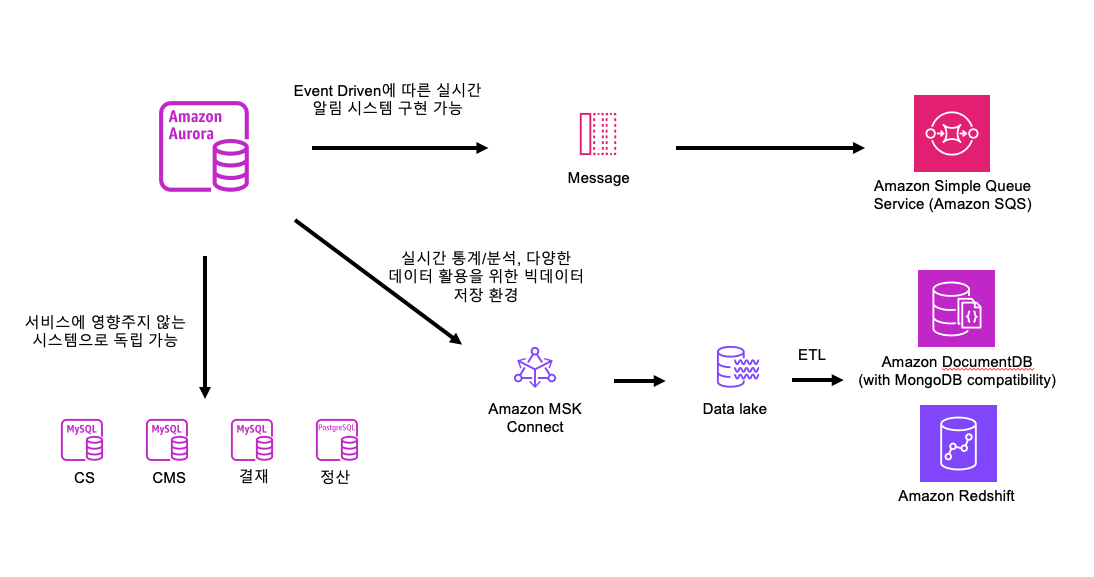
CDC를 활용한 다양한 데이터 사용환경 구현 예시
CDC를 구현하는 것은 시스템 아키텍처와 데이터 관리 전략에 큰 영향을 미치므로, 올바른 도구와 기술을 선택하고, 시스템의 요구 사항과 목표를 충족하는 방식으로 구현하는 것이 중요합니다.
Aurora for MySQL에서 CDC
- MySQL에는 Binary log라는 DML, DDL에 대한 데이터 및 DB 변경사항에 대한 명령을 기록하는 로그가 있는데 이 로그를 통해 Replication을 구현하여 고가용성을 확보할 수 있습니다. 하지만 Aurora for MySQL에서는 몇가지 이유로 binlog 활성화에 대한 옵션을 OFF가 기본값을 가지도록 설계되었습니다. 그 이유와 Aurora for MySQL에서 binlog를 사용했을때 발생하는 이슈를 알아보록 하겠습니다.
Dirty Page
MySQL과 같은 관계형 데이터베이스 관리 시스템에서, “더티 페이지”는 데이터베이스의 버퍼 풀(Buffer Pool) 내에 존재하는데, 이는 디스크의 데이터와 메모리 상의 데이터가 일치하지 않을 때 메모리 상의 페이지를 의미합니다. 즉, 더티 페이지는 버퍼 풀에 로드된 이후에 변경된 데이터를 담고 있는 페이지입니다.
더티 페이지의 개념을 이해하기 위해서는 먼저 데이터베이스의 버퍼 풀에 대해 이해해야 합니다. 데이터베이스에서 데이터를 읽거나 쓸 때, 이 작업은 직접 디스크에 액세스하는 대신 메모리에 있는 버퍼 풀을 통해 수행됩니다. 이렇게 하면 디스크 I/O를 줄이고 성능을 향상시킬 수 있습니다.
- 데이터베이스는 디스크로부터 데이터를 읽어서 버퍼 풀에 로드합니다. 이 시점에서는 버퍼 풀의 페이지와 디스크 상의 데이터가 동일합니다.
- 어플리케이션이 데이터를 업데이트하거나 삽입할 때, 해당 변경은 먼저 버퍼 풀의 페이지에 적용됩니다. 이 때, 해당 페이지는 더티 페이지로 표시됩니다. 이는 페이지가 변경되었으나 아직 디스크에는 반영되지 않았음을 의미합니다.
- 일정 시간이 지나거나 다른 조건이 충족되면, 데이터베이스는 더티 페이지를 디스크에 기록합니다. 이 과정을 플러시(flush)라고 합니다. 페이지가 디스크에 기록되면, 더티 플래그(dirty flag)는 제거되고 페이지는 다시 ‘클린’ 상태가 됩니다.
더티 페이지를 효율적으로 관리하는 것은 데이터베이스 성능과 데이터 무결성에 중요한 영향을 미칩니다. 예를 들어, 더티 페이지가 너무 오랫동안 버퍼 풀에 머무르면, 시스템 충돌 시 데이터 손실의 위험이 높아질 수 있습니다. 반면, 더티 페이지를 너무 자주 플러시하면 디스크 I/O 부하가 늘어나 성능에 영향을 미칠 수 있습니다. 따라서 적절한 균형을 찾는 것이 중요합니다.
MySQL과 같은 데이터베이스 관리 시스템은 더티 페이지 관리를 위한 여러 가지 설정과 전략을 제공합니다. 예를 들면
- 플러시 전략: 어떤 조건에서 더티 페이지를 디스크에 기록할 것인지를 결정하는 전략입니다. MySQL에서는
innodb_flush_log_at_trx_commit및sync_binlog와 같은 설정이 이에 해당합니다. - 버퍼 풀 크기: 버퍼 풀의 크기를 적절히 설정하면 더 많은 데이터를 메모리에 유지할 수 있으며, 이는 더티 페이지를 빈번히 플러시할 필요를 줄일 수 있습니다. MySQL에서는
innodb_buffer_pool_size설정을 사용하여 이를 조절할 수 있습니다. - 로그 파일 크기: 리두 로그(redo log) 파일의 크기도 더티 페이지의 플러시 빈도에 영향을 미칩니다. 로그 파일이 너무 작으면 더 자주 플러시해야 하며, 로그 파일이 크면 덜 자주 플러시할 수 있습니다. MySQL에서는
innodb_log_file_size를 조절하여 이를 설정할 수 있습니다. - 어댑티브 플러싱: MySQL의 InnoDB 스토리지 엔진은 어댑티브 플러싱 기능을 사용하여 시스템 부하에 따라 더티 페이지의 플러시 빈도를 동적으로 조절합니다.
Aurora for MySQL에서 Dirty Page
Aurora for MySQL에서 Binlog 옵션이 OFF로 되어 있는것은 이 Dirty Page와 관련이 있습니다. AWS Aurora는 전통적인 MySQL과는 다른 방식으로 데이터를 저장하고 관리합니다. 전통적인 MySQL은 InnoDB 스토리지 엔진을 사용하여 로컬 디스크에 데이터를 저장하는 반면, Aurora는 분산된 스토리지 레이어를 사용하여 여러 가용 영역(AZs)에 데이터를 복제합니다. 이로 인해 Aurora는 더 높은 내구성과 가용성을 제공합니다. Aurora에서는 각 데이터베이스 인스턴스가 공유 스토리지 레이어에 직접 쓰기를 수행하며, 이를 통해 더티 페이지의 개념이 전통적인 방식으로는 적용되지 않습니다.
즉, Aurora의 아키텍처는 각 인스턴스가 공유 스토리지에 데이터를 즉시 기록하도록 설계되어 더티 페이지를 생성하지 않습니다.
그러나, Aurora에서 바이너리 로깅(Binary Logging, binlog)을 활성화하면 상황이 달라집니다. 바이너리 로그는 데이터베이스의 변경 사항을 기록하는 로그 파일로, 주로 복제(replication) 및 데이터 복구 목적으로 사용됩니다. Aurora 인스턴스에서 binlog를 활성화하면, 인스턴스가 수행하는 모든 데이터 변경 작업이 로컬 binlog 파일에 기록됩니다. 이렇게 되면, 인스턴스 메모리에서 데이터 변경이 발생한 후 실제로 스토리지 레이어에 기록되기 전에 임시적으로 더티 페이지와 유사한 상태가 발생할 수 있습니다.
그래서 과거 버전의 Aurora DB에서 binlog를 사용하면, 데이터 변경 사항이 먼저 로그 파일에 기록되고 나중에 스토리지에 쓰여질 수 있으므로, 이 프로세스 사이에 약간의 지연이 발생할 수 있습니다. 또한, binlog를 사용하는 것은 추가적인 디스크 I/O를 발생시키므로, 성능에 영향을 미칠 수 있습니다. 공유 스토리지 레이어의 쓰기와 로컬 binlog 파일 사이에 일종의 더티 페이지 현상이 발생할 수 있으며, 이로 인해 성능과 동기화에 영향을 미칠수 있었으며, 이러한 이유로, binlog를 사용할 때는 주의하여 구성할 필요가 있었습니다.
참고 – Aurora 2.04.6 버전에서 binlog 활성화 시 성능저하를 확인 할 수 있는 우형의 테크 블로그 (
그러면 Binlog를 켜지 않는게 더 좋은 거 아닌가요?
- Aurora 2.10.x 이상의 버전에는 binlog I/O cache가 적용되어 binlog를 사용한다 하여도 성능상 이슈가 크게 없습니다.
Binlog I/O 캐시 개요
Binlog I/O 캐시는 가장 최근의 binlog 이벤트를 순환 캐시에 보관함으로써 Aurora 스토리지 엔진으로부터의 읽기 I/O를 최소화합니다. Binlog I/O 캐시는 db.t2 및 db.t3 인스턴스 클래스를 제외한 대부분의 Aurora MySQL 인스턴스에 대해 활성화됩니다.
다음 그래프에서는 binlog I/O 캐시를 켜는 경우(파란색 선)와 끄는 경우(주황색 선)에 대해 초당 평균 쓰기를 측정했습니다. 이로써 binlog I/O 캐시를 사용함으로써 얼마나 많은 처리량 향상을 얻을 수 있는지를 보여줍니다.
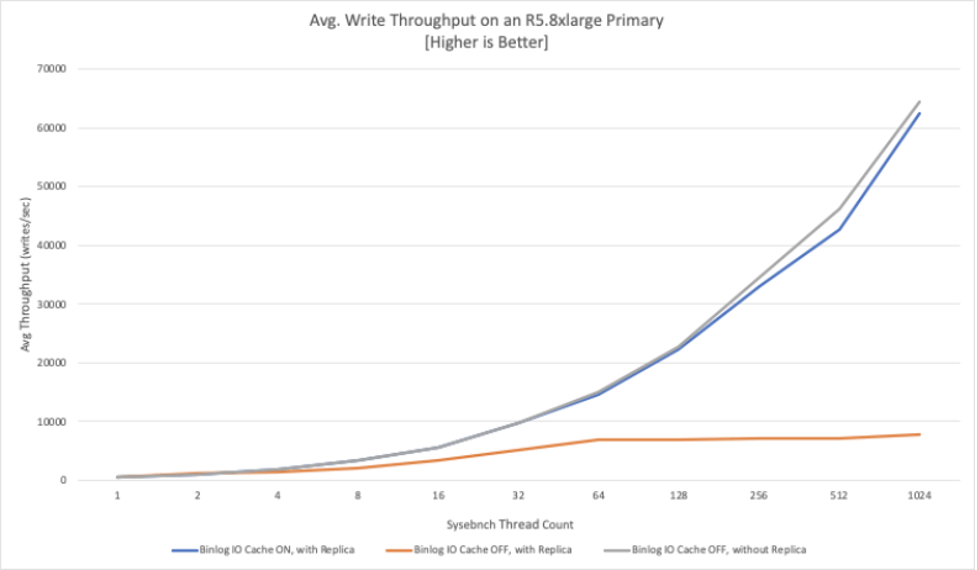
AWS에서 제공하는 binlog I/O 캐시 사용시 성능 지표
Aurora MySQL 2.10 버전은 이러한 문제를 개선하기 위해 binlog I/O 캐시라는 새로운 기능을 도입했습니다. 이 캐시는 최근의 binlog 이벤트를 메모리 내 순환 캐시에 보관하여 Aurora 스토리지 엔진으로부터 읽기 I/O를 줄입니다. 이 기능은 db.t2와 db.t3 인스턴스 클래스를 제외한 대부분의 Aurora MySQL 인스턴스에서 사용 가능합니다.
그래프를 통해 binlog I/O 캐시를 켰을 때와 껐을 때의 평균 쓰기 처리량을 비교하여, binlog I/O 캐시를 사용함으로써 얼마나 많은 처리량 향상이 가능한지를 보여줍니다. 하지만 이건 AWS가 제공하는 지표이고 서비스를 제공하는 입장에서는 늘 자기 제품은 좋다라고 설명을 하기 때문에 사실 확인을 위해 직접 성능 테스트를 진행했습니다.
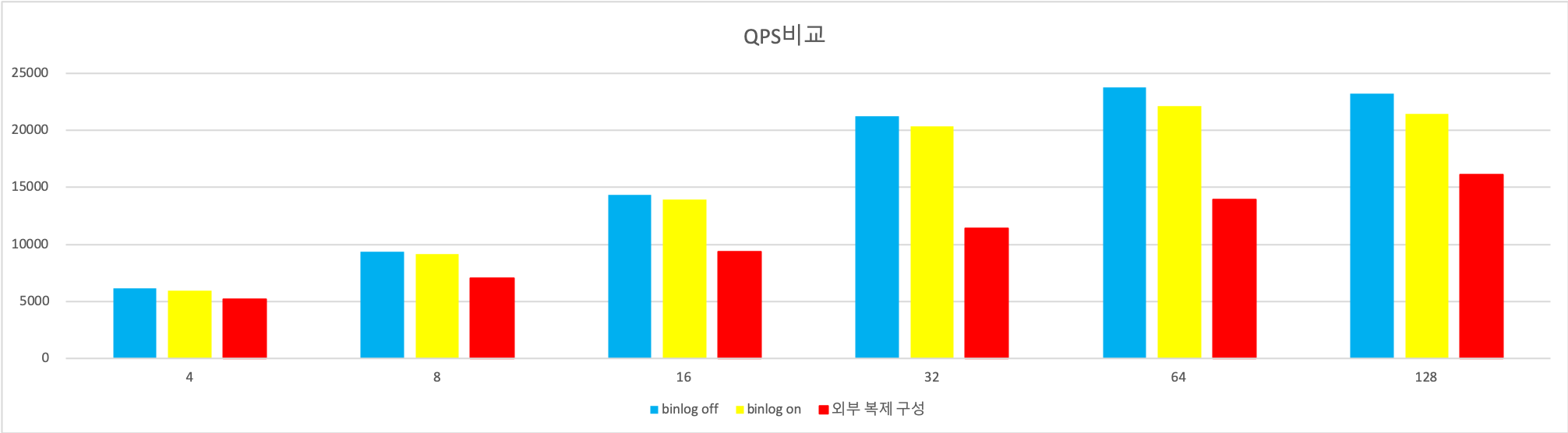
Binlog 사용에 따른 벤치마크 테스트
테스트 사양
- Source – sysbench 서버
- c6i.xlarge – CPU: 4 core, RAM: 8 GB
- percona tpcc 이용
- Target – Aurora for MySQL 2.11.1
- 인스턴스 사양: r6i.4xlarge – CPU: 16 core, RAM: 128GB
성능 테스트에 사용한 TPCC란?
Percona의 TPCC는 표준 TPC-C 벤치마크를 MySQL 데이터베이스에서 실행하기 위한 도구입니다.
TPC-C (Transaction Processing Performance Council Benchmark C)는 OLTP(Online Transaction Processing) 시스템의 성능을 측정하는 국제적으로 표준화된 벤치마크입니다. 이 벤치마크는 다중 사용자가 동시에 데이터베이스에 트랜잭션을 수행하는 환경을 시뮬레이션하며, 특히 주문 엔트리, 주문 상태, 배송, 재고 등의 다양한 업무를 모델링합니다.
TPC-C는 데이터베이스 시스템의 성능과 확장성을 평가하는 데 유용한 지표를 제공하며, 일반적으로 “tpmC” (분당 트랜잭션 수)라는 단위로 결과를 보고합니다.
Percona의 TPCC 도구는 이 표준 TPC-C 벤치마크를 MySQL 데이터베이스에서 실행하고 결과를 분석하는 데 도움이 됩니다. 이를 통해 데이터베이스 관리자 및 개발자는 시스템 성능을 측정하고, 다양한 구성과 튜닝 전략의 효과를 평가할 수 있습니다.
테스트 결과
Binlog: OFF
| Theards | qps | tps | latency avg |
| 4 | 4771.99 | 168.22 | 23.78 |
| 8 | 9291.48 | 327.72 | 24.41 |
| 16 | 17218.51 | 605.54 | 26.42 |
| 32 | 29523.49 | 1039.27 | 30.79 |
| 64 | 42895.74 | 1507.9 | 42.44 |
| 128 | 61773.73 | 2171.6 | 38.63 |
Binlog: ON
| Theards | qps | tps | latency avg |
| 4 | 4639.7 | 163.82 | 24.41 |
| 8 | 8892.96 | 313.78 | 25.49 |
| 16 | 16421.22 | 579.18 | 27.62 |
| 32 | 28099.88 | 986.54 | 32.43 |
| 64 | 41304.12 | 1454.74 | 43.99 |
| 128 | 57379.25 | 2017.8 | 63.43 |
Binlog: Repication 1 Slave Node
| Theards | qps | tps | latency avg |
| 4 | 4779.54 | 166.89 | 23.96 |
| 8 | 9136.09 | 321.77 | 24.86 |
| 16 | 16559.41 | 582.85 | 27.45 |
| 32 | 26473.12 | 930.57 | 34.38 |
| 64 | 40177.9 | 1417.42 | 45.15 |
| 128 | 57595.97 | 2025.86 | 63.17 |
Threads에 따른 QPS 변화
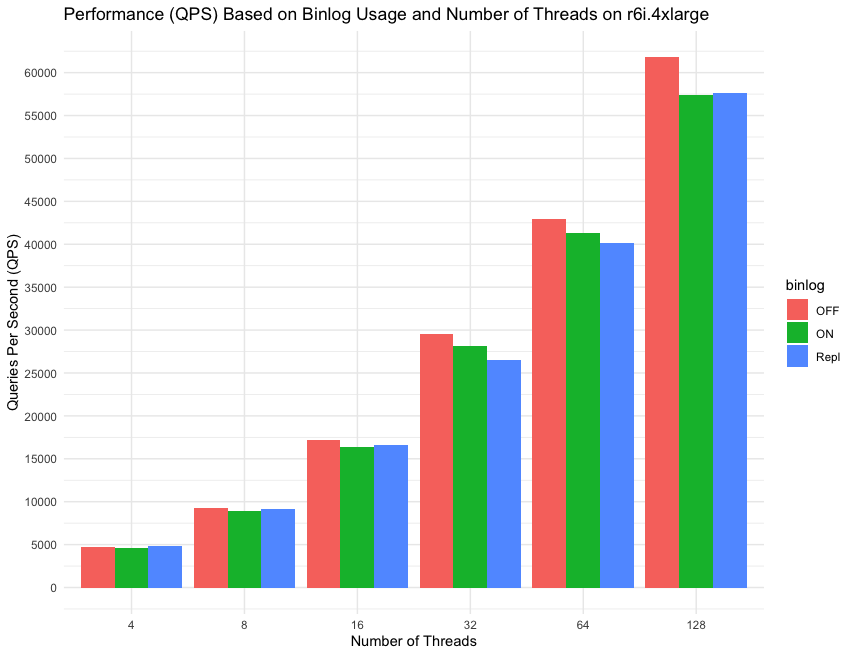
Threads 수에 따른 Latency 변화
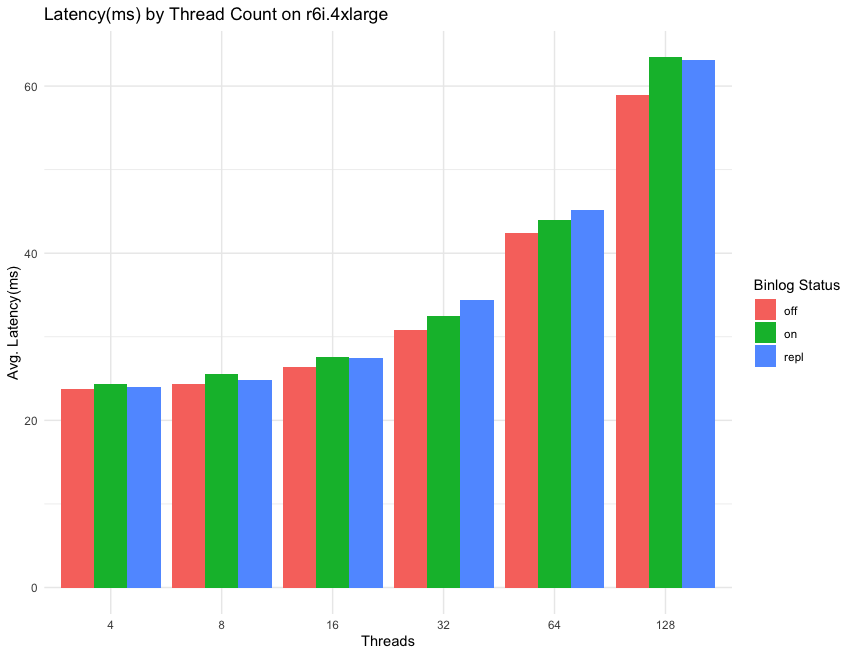
테스트로 알 수 있는 것들
- Binlog I/O cache가 적용된 이후 binlog를 활성화 해도 성능이 크게 떨어지지 않습니다.
- latency가 크게 증가하는 구간은 Threads를 32개로 증가 시킨 시점으로 운영중에는 16~32개 사이의 쓰레드를 운영 할 수 있으면 2만개정도의 QPS를 유지하면서도 최적의 DB성능을 끌어낼 수 있다.
그러면 Binlog를 어떻게 활성화 할건데?
- 앞서 말했듯이 Aurora의 binlog 설정을 기본값이 OFF입니다. Binlog를 구동하기 위해서는 MIXED나 ROW로 바꿔줘야 하는데, 해당 파라미터는 수동적 파라미터로 적용을 위해서는 DB 재부팅 과정이 필요합니다.
Binlog 적용 시나리오
- 사전에 리더 인스턴스를 추가하여 캐시에 데이터를 워밍하는 과정을 거침
- 파라미터 설정에서 binlog_format 값을 ROW로 변경. (CDC를 위한 DMS나 카프카 커넥터나 모두 ROW만 지원합니다)
- 리더 인스턴스 추가
- 기존 리더 인스턴스의 재구동 (리더가 2개 존재하는 상황으로 하나가 재구동되어도 영향이 없음)
- 모든 리더의 binlog 적용이 완료 되면 failover를 통해 기존의 리더를 라이터 인스턴스로 승격시킨다.
- 서비스 연결을 점검
Rollback 시나리오
- 파라미터 설정에서 binlog_format 값을 OFF로 변경.
- 인스턴스들을 순차적으로 재구동한다.
- 서비스 연결을 점검
특별히 인스턴스 패치를 하거나 엔진에 변경 사항이 있는 작업이 아니며, 파라미터 값만 변경해 재구동만 하면 되는 작업이기 때문에 위험도는 낮은 작업입니다.
결론
- binlog 사용시 성능 저하가 크게 없음
- 다양한 분야에 있어 binlog 활성화로 할 수 있는 것들이 더 많음 (실시간 데이터 처리, 정산 분리 등)
CDC를 준비하는 과정에 앞서 Aurora for MySQL에서 Binlog를 사용해도 큰 부하나 이슈가 없는지 테스크와 점검을 진행했습니다. 2.11.1 버전에서는 동시에 여러개의 소스로 Binlog의 데이터를 가져가는 경우 CPU 사용량이 치솟는 이슈가 있어, 2.11.2버전으로 올리라는 권고 사항이 있습니다. 그리고 최근 AWS에서 I/O 옵티마이저라는 클러스터 I/O 비용 감소 기능이 추가 되었는데 이 것을 활용하기 위해서라도 Aurora에서 Binlog를 사용하시거나 사용 계획이 있으신 분들은 2.11.2 ~ 3버전까지 업그레이드를 하는 것이 좋을 것 같습니다.
상세한 정보공유 감사합니다! 오로라는 더티페이지를 생성하지 않는건 놀랍네용!
글 잘 읽었습니다! 감사합니다.
Dirty Page 읽을 때 반복되는 문장이 있어서 말씀드립니다. 아래 문장이 반복됩니다.
더티 페이지의 개념을 이해하기 위해서는 먼저 데이터베이스의 버퍼 풀에 대해 이해해야 합니다. 데이터베이스에서 데이터를 읽거나 쓸 때, 이 작업은 직접 디스크에 액세스하는 대신 메모리에 있는 버퍼 풀을 통해 수행됩니다. 이렇게 하면 디스크 I/O를 줄이고 성능을 향상시킬 수 있습니다.
네 감사합니다. 다른 툴에 먼저 작성해 옮기다 보니 중복으로 복사된거 같네요