

회원 가입 및 로그인을 위한 테이블 설계

회원 가입 및 로그인을 위한 테이블 설계로 보는 1:1 정규화 분리
개발자의 글쓰기라는 책을 읽다보면 이런 에피소드가 나옵니다. 문장을 주고 특정 핵심 단어로 문장을 요약을 해보라고 했을때 DBA는 추려낸 단어에서 중복된 단어는 제거 해야한다고 말한다고 하죠. 이처럼 습관적으로 데이터 중복에 민감한을 표출하는 사람들이 DBA입니다.
많은 데이터베이스 이론들이 정규화의 필요성을 강조합니다. 정규화를 통해 데이터 중복을 피하고, 무손실 분해, 종속성 유지 분해의 조건이 갖춰지면 데이터 무결성, 종속성 등을 유지할 수 있습니다. 보이스 코드 정규화 (BCNF)를 구현이 가능하면 가장 좋지만, 최소 3정규화까지는 구현을 해야 데이터의 구조적인 문제에서 오는 데이터 중복을 막을 수 있으며, 데이터 중복은 불필요한 공간을 차지하는 문제 뿐만 아니라, 데이터베이스 I/O처리에서 많은 문제를 불러오기 때문에 데이터 중복을 제거하는 것은 데이터베이스를 다루는데 있어서 중요한 부분입니다.
왜냐하면 데이터베이스의 성능을 결정 짓는건 바로 I/O이며, 데이터 중복은 이런 읽기나 쓰기에 대한 I/O를 증가시키기 때문에, 많은 DBA와 DA들이 I/O를 줄이기 위하여, 정규화를 하고 SQL튜닝을 하고 하는 것이죠.
데이터의 속성에 따라 정규화 할 필요가 있다고 이론서들은 늘 말합니다. 하지만 그 속성을 어떻게 나누고, 분류할 것인지 결정하는 것은 어려운 문제입니다. DBA나 DA가 없는 상황에서 개발자들이 서비스에 필요한 수준으로 설계해서 구성된 DB들은 이런 기본적인 원칙이 잘 지켜지지 않습니다. 후에 DB 성능에 문제가 발생한 시점에서는 구조적인 문제가 너무 엉망으로 얽히고 꼬여있어서 손을 댈 수 없는 상황이 많습니다.
1:1 항목에 대해서는 굳이 테이블 분리를 할 필요가 없다라고 말하시는 분들도 있습니다. 하지만 데이터가 많아지고, 서비스가 커지면 한 테이블에 너무나 많은 컬럼이 담겨 있어 문제가 되는 경우가 반드시 발생합니다.
데이터베이스는 인덱스를 사용하던, 풀스캔을 하던, 특정 값을 읽어오기 위해서는 그 값이 들어있는 row의 전체 블록에 대한 읽기 작업이 선행됩니다.

- 인덱스를 통해 해당 값이 있는 row에 도착하지만,
- Row값의 일부분인 해당 값만 읽어오는 것이 아니라 해당 값이 있는 Row 전체 블록을 읽어온다.

회원 테이블의 비지니스 로직과 구조화하기
유저 테이블 경우 한번 구성을 하게되면 거의 모든 서비스에서 참조하는 테이블입니다. 따라서 유저 테이블은 불필요한 데이터가 많다거나 컬럼이 많다거나 하면 좋지 않아요. 그리고 속성이 다른 데이터들이 많아 1:1 매칭이 되더라도, 정규화를 하여 분리하는 것이 좋습니다.
회원 테이블은 회원 가입과 로그인에 가장 먼저 사용되고, 이후 서비스가 돌아가면, 정산을 한다거나 통계나 서비스 이용 목록 등을 조회할 때 계속 사용이 됩니다.


RDBMS 테이블 설계
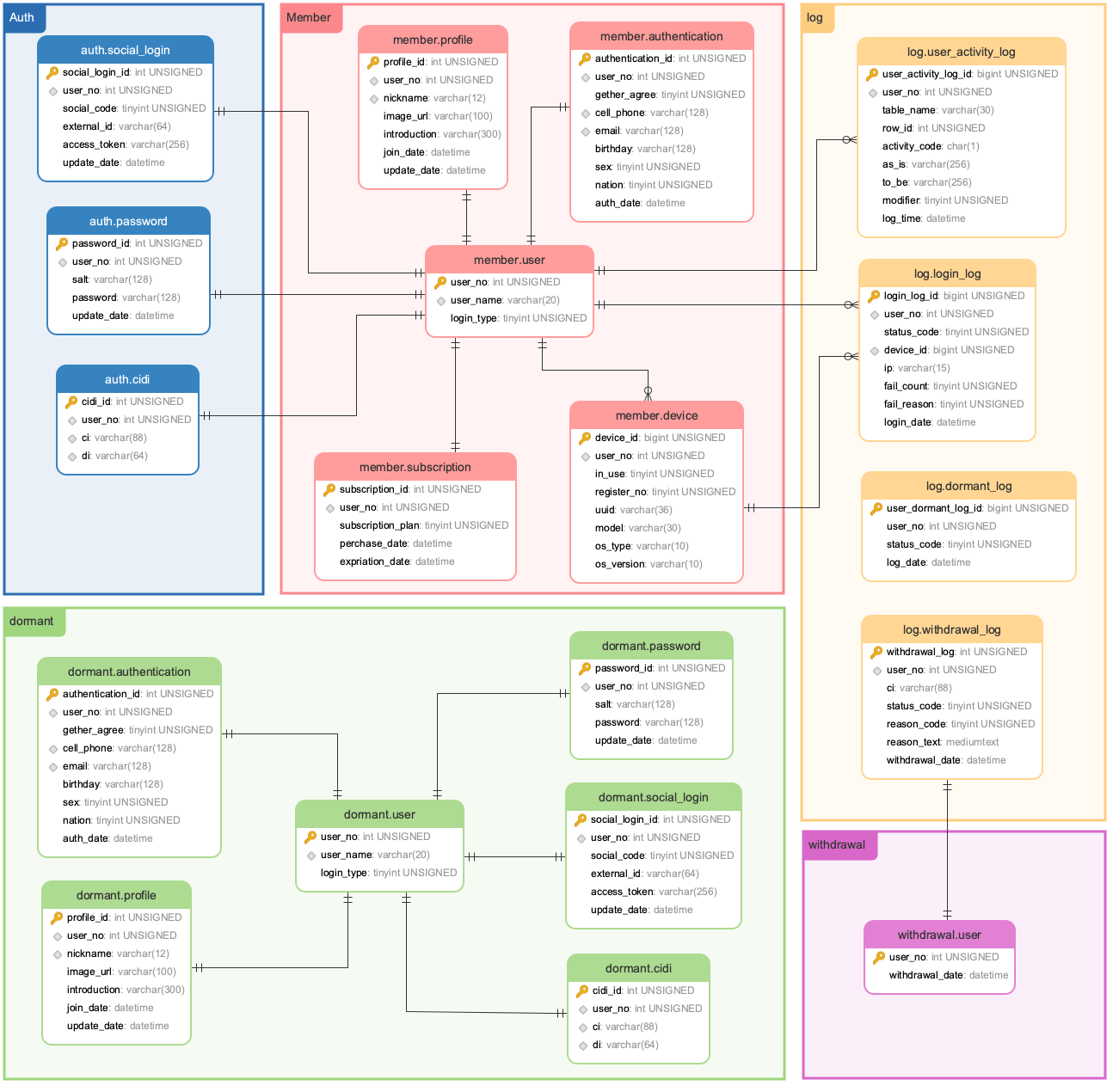
member 스키마부터 살펴 보겠습니다.
member.user
- 가장 기본적인 회원 ID을 저장하는 방식인데, user_name 은 일반적으로 사이트나 서비스에서 회원 가입을 할때 사용하는 ID라고 보시면 됩니다.
- MySQL의 경우 user_no를 auto_increment 옵션을 통해 순차적으로 배당 받는 방법을 사용했지만, 오라클이나 PostgreSQL에서는 별도의 시퀀스 테이블을 이용해 구현하는 방법을 사용합니다.또, 요즘은 auto_increment를 통한 user_no, user_id 등을 할당하는 것 대신 uuid 함수를 이용해 uuid 36자를 이용해 유저의 고유 식별 코드를 생성하는 경우도 있습니다. uuid 36자를 binary 16byte로 변경해서 저장하는 방법을 사용하기도 합니다.
- 최소한의 데이터로 구성을 해놓으면 휴면(dormant)으로 넘어 갈때, 혹은 탈퇴(withdrawal)할때 까지는 어떤 update도 하지 않고, 계정정보가 휴면이나 탈퇴로 변경시 delete 하는 것으로만 제한됩니다.
member.authentication
- 회원의 인증 정보를 담습니다. 암호화가 필요한 개인정보는 오직 테이블에 담기는 구조로 설계한 것이고, 후에 배송이나 주소록이 필요하다면, 별도로 주소록 테이블만 암호화를 하면 됩니다.
- 개인 정보를 담는 이유는 서비스가 어느 정도 진행하고나서 좀 더 나은 방향으로 개선점을 찾기 위해서는 우리 서비스에는 어떤 유저가 있고, 어떤 연령층이 있고, 성별이나 그런 정보들이 필요합니다. 즉 서비스에 대한 통계 정보를 위해 개인 정보를 담는 것이 필요할 수 있기 때문에 이렇게 설계하였고, 해당 정보는 본인 인증 서비스를 해주는 타업체의 인증을 통해 가입하는 경우만 기록이 됩니다.
member.profile
- 유저가 직접등록하는 정보들인데, 닉네임과 프로필 사진은 앱서비스에서 자주 여기저기서 불려다니는 데이터입니다.
- 다른 데이터들은 자주 불려오는 데이터들은 아니지만 대부분 회원 조회나 유저의 닉네임을 클릭했을때 일반적으로 같이 보여지는 데이터들 입니다.
member.subscription
- 요즘 앱서비스는 구독서비스를 많이 하는데, 해당 유저가 무료 이용자 인지, 유료하면 어떤 플랜을 사용하는지에 대한 정보들을 기록해 둡니다 .
- 로그인 할때, session 정보와 함께 캐싱해 두면 로그인할때 빠르게 처리할 수 있습니다. (session 정보는 redis 같은 캐시를 이용하는 편이 좋습니다.)
member.device
- 유저가 로그인하는 기기 정보를 담습니다. 어떤 기기가 많이 들어오는 통계 정보를 수집하고, 사용자 기기에 대한 대수 제한을 위함이며, 인증 되지 않은 기기의 사용을 제한하여 보안성을 높이는 것이죠.
그 다음은 auth 스키마 입니다.
auth.password
- id 방식으로 가입한 경우 password를 받습니다. 소셜 로그인과 id 방식이 혼재 된경우 password를 user 테이블이 같이 기록하면, password가 null 값을 가지는 경우가 발생합니다. 정규화를 통해 이런 부분을 최소화 하고, sql 인젝션에 대한 보호을 위해 이처럼 분리해두는 것이 좋습니다.
- 패스워드는 sha-512, salt 값은 (base64)를 통해 암호화하는 것이 나중에 isms나 ipo를 위한 내부 감사 대응에도 좋습니다.
auth.social_login
- 소셜 로그인을 하게 된다면 저장하게되는 정보인데, 굳이 테이블을 소셜 서비스 단위로 나눌 필요없이 social_code 값을 통해, (1:apple, 2:goolge, 3: kakao, 4:naver …) 처럼 구분하여 externale_id와 access_token값을 기록하면 됩니다.
- 소셜 로그인으로 가입을 하게되면, user_no를 자동으로 생성하고, user_name에 랜덤 ID를 부여하는 프로세스를 추가해야합니다.
auth.cidi
- cidi 값은 본인 인증업체, 휴대폰 인증이나 ipin 같은 업체로부터 본인 인증 절차를 거쳤을 시에 받는 고유값입니다.
- ci는 흔히 암호화된 온라인 주민 번호라고 하며 어떤 업체에서 인증을 받더라고, 한사람에게 하나의 값만 부여됩니다.
- di는 사이트 중복 가입을 방지하는데 사용한다고 하는데, 이건 인증 업체마다 다른 값이 올 수도 있기 때문에 사용하는데 주의가 필요합니다.
휴면(dormant) 스키마 입니다.
- member 스키마의 오브젝트 들에 대해 특별한 FK값을 가지고 있지는 않지만, 감사 규정상 반드시 스키마 이상으로 분리되어야 하는 스키마이며, 휴면에 빠진 회원 정보는 member에서 delete하고, 기존 값을 그대로 dormant로 옮기는 작업이 이루어 집니다.
- member 뿐만 아니라 auth 의 데이터들도 옮겨와 휴면 회원의 데이터는 전부 한곳에 자리하게 됩니다.
- 휴면 스키마로 옮겨온 시점으로부터 회사 정책에 따라, 1,3,5년 등의 단위로 복구 하지 않는 회원을 대상으로 공지와 함께 자동 탈퇴처리 하는 프로세스를 가지게 됩니다.
탈퇴(withdrawal) 스키마 입니다.
- 탈퇴한 회원에 대한 개인정보는 가지고 있을수 없으나, 회사 정책을 사전에 통보했다면, 결제에 대한 환불 등에 대해 고지 할 수 있는 연락처 정도는 가지고 있을 수 있습니다.
- 또한 탈퇴한 회원이 재가입하여 가입시에만 받는 혜택등을 중복하여 받지 않게 하도록 ci 정보등을 일정 기간 저장할 수 있습니다.
- 탈퇴의 경우 서비스에 따라 구성 내용이 많이 바뀌기 때문에 오브젝트들을 구성하지 않았고, Billing 테이블이나 ci 정보등을 별도로 남기는 테이블들을 구성하거나 withdrawal 테이블에 컬럼으로 기록할 수도 있습니다.
Log 스키마의 오브젝트들을 보면 기존 테이블과 구성이 다릅니다.
- 로그를 설계하는데 있어 많은 개발자들이 실수 하는 부분이 테이블의 row값을 그대로 복사해서 날짜만 붙이는 것인데, 로그의 설계 원칙은 모두 코드값으로 표현되어야 하는 것이 기본입니다. 코드만 보고 이게 어떤 행동이 어떻게 발생한 것이다 라는것을 알 수 있어야 합니다.
- 데이터 중복을 만드는 것보다 행위의 결과, 원인 등을 나타내는 것을 기본으로 해야 합니다.
앱서비스에 필요한 기본적인 테이블 설계를 통해 어떻게 1:1 매칭 데이터들이 어떤 속성을 가지고 분리 되는지 위 ERD 모델을 보고 천천히 분석해보면 테이블 모델링에 대해 조금은 이해가 되지 않을까 해서 그려봤습니다.
또한 14세 미만 부모 동의나 성인 인증이 필요한 경우도 저 모델에서 어디에 어떻게 추가하면 될까 스스로 고민해보시면 앞으로 새로운 설계를 하는데 많은 도움이 될 것이라 생각합니다.
1:1 정규화를 통해서 join을 해야하는 테이블들 간의 블록 읽기를 최소화 하면 데이터 출력 속도도 빠르게 유지할 수 있고, 속성 별로 테이블을 분리 했기 때문에 적재적소에 필요한 컬럼이나 별도의 테이블을 추가해서 서비스를 늘려가는 것이 어렵지 않습니다.
테이블정의서를 첨부합니다.
잘 읽었습니다!
테이블이 아름다울 정도로 잘 만들었습니다.
감사합니다.
게시글 잘 읽었습니다. 혹시 log.user_activity_log테이블은 어떠한 데이터들이 담기는지 설명해주실 수 있나요?
정의서에 따로 없어서 컬럼 comment 확인이 어려워서요~
부탁드리겠습니다!
아이고 정의서에 있었네요 감사합니다!
좋은 포스팅 잘 읽었습니다. 감사합니다.
질문하나 드리겠습니다. member 스키마의 member.user 테이블에서 user.no가 PK로 설정되어 있고 나머지 테이블들이 FK로 이용하고 있는데 user_no을 member.profile, member.authentication, member.subscription, member.device 테이블의 PK로 사용하지 않고 profile_id, authentication_id, subscription_id, device_id로 따로 PK를 주신 이유를 알려주실 수 있을까요??
그 부분은 MySQL을 사용하면서 그냥 그렇게 설계한 부분입니다. user_no로 동일하게 사용해도 되요. 다만 트랜잭션 처리가 소스단에서 완벽하게 구현되지 않으면 모두 FK를 걸어서 사용해야 하는데.. 결국 FK가 많은 경우 데이터가 많아질 경우 DML 처리에서 굉장한 지연이 발생합니다. FK는 ERD에서 논리적으로만 표현을 해둘뿐이고 실제 물리 설계시 잘 넣지 않는 부분이라서요. device의 경우는 1인 1기가 아니라 여러개의 기기를 사용할 수 있기 때문에 별도로 id를 딴것이구요. 1:1 매칭 테이블은 소스단에서 트랜잭션 처리를 완벽히 할수 있다면 FK없이 동일한 값으로 PK를 처리하셔도 됩니다. 하지만 MySQL에서 소스단에서 완벽하게 트랜잭션을 처리 하지 못할 것 같다면 그냥 저렇게 따로 별도의 PK를 두는것도 괜찮습니다.
안녕하세요! 회원 관리 쪽 서버 API를 설계 및 구현하러 찾아보다가 RastaLion님의 블로그 글을 읽게 되었습니다.
친구들끼리 하는 프로젝트라 법적 문제나 DB 성능, 로그 설계 등 고려하고 있지 않았던 부분이 많았는데, 읽으면서 정말 많은 것을 배웠습니다.
읽으면서 한 가지 질문이 생겼는데요, “스키마를 통한 분리를 하는것은 SQL 인젝션 공격에 대한 방어”라고 하셨는데, 혹시 이게 어떤 의미인지 더 자세히 설명해주실 수 있을까요?
SQL 인젝션은 클라이언트에서 악의적인 SQL문을 전송해서 서버의 DB에 조작하는 것으로, 백엔드에서 입력을 검증하거나, 해당 입력을 곧장 SQL문의 input으로 들어가지 못하게 해서 막는다고 알고 있습니다. 스키마를 분리하면 해커가 한 스키마의 테이블 목록을 알아내도 다른 스키마의 테이블 목록을 알아내지 못해서 방어가 되는 걸까요? 그러거나 스키마 별로 권한을 다르게 해서 DB 접근을 막을 수 있어서일까요? 한 프로젝트에서 여러 스키마를 사용해본 적이 없어서 여러모로 생각해봐도 정확한 답을 모르겠어서 질문 드립니다.
감사합니다.
추가로, 현업에서는 관리자 테이블을 따로 만드는지도 궁금합니다!
이 글을 읽고 개인정보취급자에 대한 권한 관리의 중요성도 따로 찾아보게 되었는데, 현업에서는 이것을 다른 관리자 테이블+관리자 접속 로그 테이블로 분리해서 사용하나요?
해커가 DB에 직접 접근할 수 있는 상황까지 갔을때를 방어하기 위한 로직입니다. 일반적으로 클라우드 환경이라면 lb를 통해서만 서비스에 접근이 가능하게 설정 했다면 이런 문제는 거의 발생하지 않아요. 만약 퍼블릭 접근이 가능한 api 서버나 DB가 있고 해커가 api에서 DB 접속정보를 탈취했을 때 해당 서버를 이용해 DB에서 직접 select 쿼리를 날려서 데이터를 수집이 가능합니다. 생각하신대로 하나의 스키마에서 모든 정보를 스캔할수 없고, 스키마 별로 권한 분리를 할 수 있기 때문에 방어할 수 있다라고 말한게 맞습니다. 서비스의 db계정에 auth 스키마에 대한 전체 접근 권한아니라 테이블 권한만 있다면 그 계정이 확인할 수 있는 DB 스키마 리스트에 나오지 않기 때문에 원하는 정보를 얻기위해 좀 더 많은 시간과 노력이 필요하죠.
그리고 많은 회사가 관리자 테이블을 DB에 별도로 만들지는 않고 접근제어 시스템을 따로 두는 편입니다. 솔루션 구매이죠 원래 DB에는 AUDIT 기능이 있어 이런 유저 접근 제어를 통제할수 있어요. 하지만 DB자체에 대한 부하가 발생하기 때문에 접근제어 솔루션을 두어 관리를 합니다.
글 내용이 너무 좋네요. 잘 읽었습니다.
하나 궁금한게 있는데요~
개념 설계하신 – 회원 가입 로직 이미지와
물리 설계 – RDBMS 테이블 설계
이것들은 어떤 툴을 사용하셔서 그리신건가요?
나비캣 데이터모델러 입니다.
정말 잘 읽었습니다. 감사합니다.
사이드 플젝 하다가 테이블설계 막막해서 서치좀하다가 오게되었습니다..! 너무 잘 읽었습니다..! 혹시 궁금한게 탈퇴를 하게되면 개인정보를 가질 수 없다고 하셨는데 탈퇴를 하게 되면 member 와 auth, dormant 스키마의 모든 내용도 delete 되는건가요??
일반적으로는 삭제를 해야하는것이 맞고 ci 정보의 경우 탈퇴후 재가입을 통한 중복 혜택 방지등을 이유료, 개인정보 수집 동의 하에 탈퇴후 몇년가 가지고 있겠다 고지 후에 보관하는 경우도 있습니다.
정말 잘 읽었습니다.
N회 로그인 실패 시 로그인 제한에 관한 부분은 어디에서 처리하시는지 여쭤봐도 될까요?
원하는 대로 구현하시면 됩니다. 별도의 스택을 쌓는 테이블을 만들던지, 레디스 같은 세션 캐시에서처리 하던지 말이죠.