

MongoDB 복제 아키텍처

MongoDB 복제 아키텍처
MongoDB는 Secondary가 Primary에서 OpLog를 가져온 다음 OpLog를 재생해서 데이터를 동기화합니다. Secondary멤버는 Primary뿐만 아니라 다른 Secondary 멤버의 OpLog를 재생할 수도 있습니다.
OpLog
OpLog는 Operation Log의 약자로, MongoDB의 복제를 위해서만 사용됩니다. 컬렉션의 레코드 형태로 저장되기 때문에 저널로그와는 다른 방식으로 기록이 됩니다. OpLog와 저널로그의 차이는 주체가 다르다는 점으로 OpLog는 MongoDB의 엔진이 처리하며, 저널로그는 스토리지 엔진이 처리를 합니다.
OpLog의 구조
OpLog는 MongoDB의 Local 데이터베이스안에 ‘oplog.rs’라는 컬렉션으로 기록됩니다. 항상 모든 필드가 존재하는 것은 아니며, 필요에 따라 생성되는 필드도 존재합니다. 아래는 oplog.rs의 필드 값의 내용입니다.
- ts(Timestamp): 저장순서를 결정. 동기화를 잠시 중단하거나 재시작할 때 기준.
- t(Primary Term): 레플리카 셋의 Primary 선출하는 투표가 실행시 증가.
- h(Hash): OpLog의 도큐먼트는 Primary 멤버에서 실행된 데이터 변경작업을 의미, 각각의 작업에는 OpLog의 해시 값을 이용해서 식별자가 할당되는데 이 식별자를 h 필드에 저장.
- v(Version): 도큐먼트의 버전을 의미.
- op(Operation Type): i(Insert),d(Delete),u(Update),c(Command),n(No Operation) 등 오퍼레이션 종류를 저장. n은 단순 정보 저장.
- ns(Namespace): 데이터가 변경된 컬렉션의 네임스페이스가 저장.
- o(Operation): op필드에 저장된 오퍼레이션 타입별로 실제 변경된 정보가 저장
- o2(Operation 2): op필드가 u인 경우에만 o2 필드가 존재. 업데이트 될 대상 도큐먼트의 _id 정보를 저장.
Local Database
MongoDB의 기본 데이터베이스의 하나로 MongoDB를 설치하면 기본으로 생성되는 데이터베이스 입니다. oplog.rs를 포함하여 해당 데이터베이스만을 위한 정보들이 담긴 컬렉션인 저장되어 있습니다. Local 데이터베이스 안의 내용들을 Secondary로 복제되지 않기 때문에, 복제할 필요가 없는 모니터링 데이터 및 백업 이력등을 Local 데이터베이스에 저장하여 관리할 수 있습니다. Secondary 멤버들이 Mongo Shell에서 명령어가 입력되지 않지만, 그들이 가진 local 데이터베이스에는 데이터 입력, 수정 및 삭제가 가능합니다.
Initial Sync (초기 동기화)
MongoDB를 처음 설치 후 비어있는 데이터베이스를 레플리카 셋에 투입하면 이미 투입되어 있는 멤버들로부터 모든 데이터를 일괄적으로 가져옵니다. 특별히 사용자가 작업을 따로 해주지 않았다면 자동으로 초기 동기화가 발생하고, 초기 데이터를 복제하며, 복제가 끝난 후에 복제하는 동안 발생한 변경사항을 OpLog를 가져와서 재생하여 적용한 후 최종적으로 인덱스를 생성하여 동기화가 마무리 됩니다. 이런식의 자동 초기 동기화는 데이터가 많은 경우 시간이 매우 오래걸리기 때문에 다른 레플리카 멤버의 데이터 파일을 복사한 후 레플리카 셋에 투입할 수 있습니다. 이 경우 데이터 파일을 복사하기 위해 해당 소스 DB를 종료한 상태에서 복사해야 하며, LVM 스냅샷 백업등을 이용해서 초기 데이터를 가져오는 것도 가능합니다.
실시간 복제
복제가 시작된 후 시간이 지나고 언젠가는 Primary와 Secondary의 데이터가 동기화 되는 것을 최종 일관성이라고 표현합니다. 그리고 Primary 멤버는 모든 멤버의 복제 상태 정보를 가지고 있습니다.
MongoDB의 복제 아키텍처를 그림으로 그리면 아래와 같습니다.
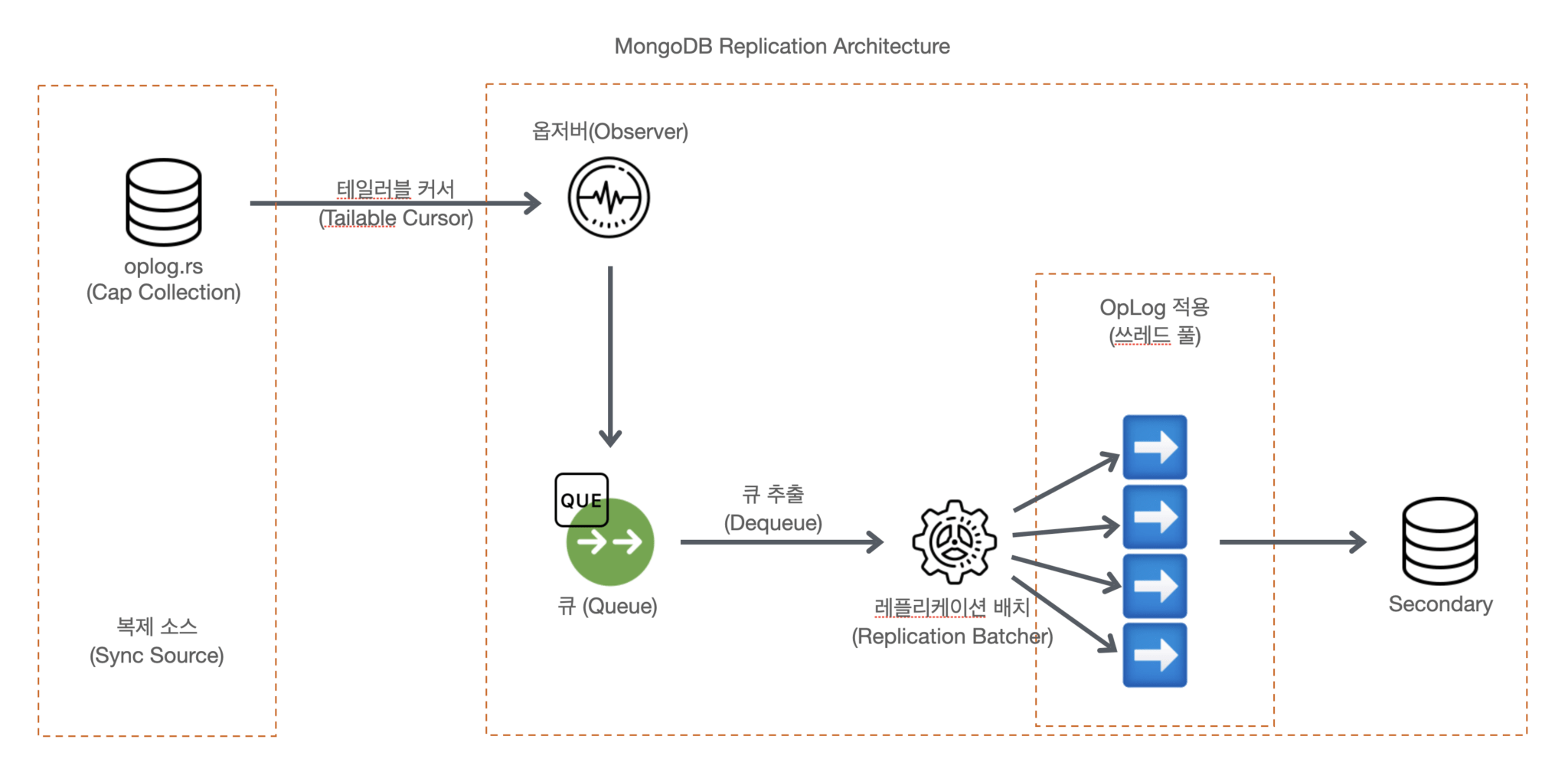
MongoDB의 복제 아키텍처
- MongoDB가 처리한 모든 데이터 변경 내용을 Cap 컬렉션 구조의 ‘oplog.rs’ 컬렉션에 저장
- 테일러블 커서[1]를 통해 최신 데이터 전송한다.
- Secondary의 백그라운드 쓰레드(Observer)[2]의해 큐에 일정 개수의 OpLog를 담는다.
- 리플리케이션 배치[3] 쓰레드는 큐에서 일정 개수의 OpLog를 가져와 OpLog 적용 쓰레드[4]에 맞게 작업량을 나눈 다음 작업을 요청한다.
-
- [1] 테일러블 커서: Cap 컬렉션에서 지원하는 리눅스의 Tail 이 화면에 보여주는 것처럼 큐 방식으로 동작하는 커서
- [2] Observer: Secondary 멤버의 OpLog 수집을 위한 백그라운드 쓰레드. 수집하여 큐에 쌓는 역할만 한다.
- [3] 리플리케이션 배치: 큐에서 OpLog를 가져와 적용 쓰레드 개수에 맞게 작업량을 나눈 다음 작업을 요청
- [4] OpLog 적용 쓰레드(Applier): 기본값으로 16개를 사용하고 쓰레드는 각각 5,000개의 OpLog의 아이템을 담으 수 있는 자체 캐시 메모리를 갖고 있다. 최대 512MB의 메모리를 사용할수 있게 제한되어 있으며, 16개의 OpLog 적용 쓰레드 전체 8GB의 자체 캐시 메모리를 사용할 수 있다.
OpLog의 컬렉션 크기 설정
oplog.rs의 컬렉션 크기에 따라 OpLog에 데이터를 얼마나 담을수 있느냐가 결정되는데, 이 크기에 따라 Secondary 멤버의 허용가능한 지연시간이 결정됩니다. OpLog의 크기를 명시하지 않으면 Disk Free space에서 5%정도를 OpLog의 크기로 결정합니다.
OpLog의 정보 확인
db.getReplicationInfo(): JSON 포맷의 결과db.printReplicationInfo(): 단순 텍스트 포맷의 결과
참고 자료
도서 : 맛있는 몽고DB
도서: Real MongoDB
도서: 오픈소스 몽고DB
도서: MongoDB in Action
MongoDB Manual: https://docs.mongodb.com/manual/
참고해서 발췌해가요~~♥