

Graph DB? 그래프 데이터베이스
![]()
Graph DB?
오랜만에 글을 쓰는거 같네요. 현재 이런저런 일도 많이 있고 방송대 전공 과목의 과제와 기말시험을 대비한 공부를 하느라 포스팅이 소홀했습니다. 기말 공부를 하던중에 머리도 식힐 겸 Graph DB를 조금 알아보았습니다.
NoSQL를 많이 사용하고, 많은 기업에서 NoSQL 전문가들을 찾는데, NoSQL에 포함된 여러 데이터베이스들은 각각 자기만의 아키텍처를 가지고 있습니다. 따라서 MongoDB를 좀 다룬다고 해서 Graph DB인 Neo4j 혹은 Arango 같은 GraphDB 타입의 NoSQL을 다룰수 있다는 아니고 역시 공부가 좀 필요하더군요.
일반적으로 GraphDB라고 했을때 어떤 생각이 떠오르시나요?
그래프 라는 것은 일반적으로 통계를 나타낼때 사용하는 막대 그래프 같은 통계나 수치를 보여주는 것이 가장 먼저 떠오르지 않을까 싶네요. 또는 IT업계 분들이라면, 뭐 그래픽 카드의 성능을 이용하는가 라고 생각할 수도 있을것 같습니다.
GraphDB는 이런것들과 전혀 관계 없으며, 그래프는 꽤 오래된 개념으로 스위스의 수학자 레온 하르트 오일러의 학술 논문에서 처음 기술 되었습니다. 그는 쾨니히스베르크의 7개의 다리로 알려진 문제를 해결하기 위해 노력중이었고, 이 문제는 요즘에는 수학을 공부하는 학생이라면 한번쯤 본적이 있을 겁니다.

쾨니히스베르그의 7개의 다리
- 7개의 다리는 도시의 4개의 서로 다른 지역과 연결되어 있음
- 도시 곳곳을 둘러보고 모든 다리를 두 번 건너지 않고 모든 다리를 건너는 것
오일러는 자신이 만든 수학 공식을 이용해 이 문제를 해결 했는데, 이 과정에서 짝수 개의 다리가 없다는 것을 증명함으로써 문제를 만족하는 산책을 할 수 없다는 것을 증명 했습니다. 이과정에서 나온 것이 바로 그래프이며, 그래프 이론의 시발점이 되는 것이죠.

쾨니히스베르크의 모델
이렇게 탄생한 그래프를 정의한다면, “연결되어 있거나 서로 관련이 있는 2개 이상의 실체를 추상화하여 수학적으로 표현한 것” 입니다.
수학에서는 위 그림에서 빨간 원으로 표시된 부분을 정점(Vertex)라고 하지만, GraphDB에서는 노드라고 표현합니다.
정점을 잇는 선들을 Edge라고 표현하며, GraphDB에서는 엣지를 통해 각각의 노드들이 서로 연결되어 있는 구조를 통해 그래프가 생성됩니다.
이처럼 오일러의 모델과 알고리즘을 이용하여, 그래프를 사용해 모델링과 솔루션 패턴을 연구하는 과학 분야를 그래프 이론이라고 부릅니다. 그리고 그래프의 유형에는 여러가지가 있습니다.
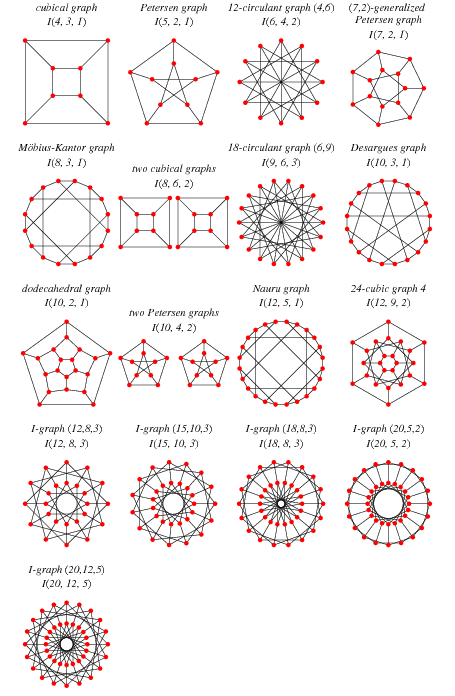
그래프의 유형
현재 GraphDB의 대표적인 데이터베이스는 Neo4j입니다. 그리고 Neo4j 말고도 arangoDB 같은 다양한 GraphDB들이 있습니다.
GraphDB들은 NoSQL의 범주에 들어 있지만, 일반적인 NoSQL의 데이터베이스들과는 많이 다른 특징을 보여주는데 바로 모든 작업을 그래프와 그래프 이론을 통해 동작한다는 것입니다.
GraphDB의 특징
그래프를 이용하여 데이터를 탐색하는 경우의 가장 큰 장점은 인덱스를 이용하지 않아도 연결된 노드를 찾는 것이 빠르다는 것입니다. 노드와 노드간의 관계를 이용해 인접한 관계를 찾는 기능인데 index free adjacency라고 합니다. 이처럼 관계를 이용한 정보를 탐색하는데 강력하고, 관계형 데이터베이스보다 관계를 표현하는데 있어 더 직관적이며, 왜곡 없이 표현할 수 있습니다. RDBMS에서 10개 이상의 테이블을 조인하게 되면 테이블의 사이즈, 데이터양, 조인 순서들 많은 부분을 고려하여도, 성능저하가 발생하는 것을 막을수가 없지만, GraphDB는 이런 복잡한 연산을 처리하는데 적합한 그래프 이론을 알고리즘으로 채택하고 있습니다.
다른 NoSQL과 마찬가지로 스키마가 없는 구조로 되어 있으며, 반정규화된 데이터를 처리하는데 적합합니다. 노드는 RDBMS의 테이블과 비교할 수 있는데, 노드는 테이블이 행/열의 데이터를 가지고 있는 것과 같은 속성을 가지고 있습니다.
GraphDB에서 관계는 항상 시작과 끝점이 있는 방향을 가지고 있는데 , 자체 참조가 가능하여 시작과 끝이 동일 노드가 될 수도 있습니다. 관계는 명시적이며, 노드 처럼 속성을 가질수도 있습니다.
GraphDB를 어디다 사용해야 할까?
4~6개 이상의 테이블을 이용하는 복잡한 질의를 해야한다면 GraphDB가 좋은 대안이 될수 있습니다. 인덱스를 이용해 시작 노드를 찾고 index free adjacency를 이용해 해당 노드에 연결된 관계만들 탐색합니다. 패턴이 일치하지 않는 것들은 무시하고 넘어가기 때문에 연결된 패턴을 찾는데 있어서는 매우 빠른 속도를 보장합니다. 노드의 데이터 크기와 쿼리의 성능이 독립적이기 때문에 데이터 사이즈가 늘어난다고 해서 성능의 저하가 발생하지 않습니다.
비지니스 인텔리전트 시스템에서도 강점을 가지고 있습니다. 실시간으로 데이터를 복제하고 반정규화하고 추출, 변환 및 적재 하는 작업를 큐브라고 하는데, GraphDB에서는 데이터를 많이 복제하지 않아도 되는 데이터에 대해 요청과 응답을 실시간으로 업데이트 할 수 있습니다.
서로 다른 데이터들이 어떻게 연관되어 있는지 확인하는 경우에도 GraphDB는 강점을 보입니다. 시작과 끝이 되는 노드만 알려주고 그래프 이론을 적용하기만 하면 되기 때문이죠.
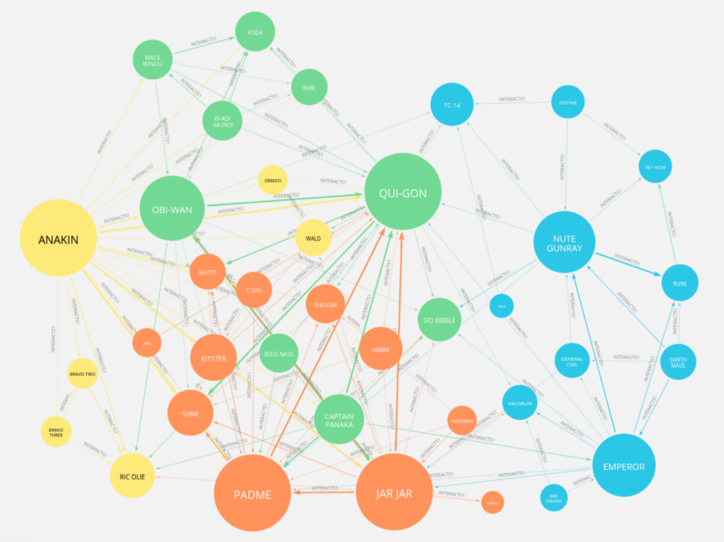
GraphDB를 사용하지 말아야 하는 경우
모든 데이터베이스들이 그렇듯, 강점이 있으면 약점도 있습니다. GraphDB에서 피해야 하는 작업은 대규모 집합지향 쿼리, 글로벌 그래프 작업, 간단한 집계 중심 질의입니다.
어려 항목을 확인하는데 있어 많은 조인과 집계 연산이 필요하지 않고 단순히 데이터를 취합하는데 사용한다면 관계형 데이터베이스보다 나은 성능을 제공한다고 할 수는 없습니다.
GraphDB는 로컬 그래프를 처리하는데 있어서는 뛰어나지만, 노드 클러스터를 찾고, 노드 사이의 알려지지 않은 관계 패턴을 발견하고 그래프 구성요소의 중심 및 구역 사이를 정의하는 작업, 다시 말해 그래프 전체를 보는 글로벌 그래프 작업에는 성능적으로 많은 자원과 시간을 소모합니다.
앞서 말했듯 GraphDB는 복잡한 연산에 최적화 되어 있는데, 반대로 복합성이 낮은 단순한 구조의 간단한 질의들이 GraphDB에서는 상당히 비효율적으로 처리됩니다.
이렇듯 단점도 있으니 무조건 성능이 잘나오더라가 아닌 어떤 시스템을 구축하느냐가 가장 중요합니다.
GraphDB를 간단히 알아보았고, 정확히 어떻게 동작하고, 어떻게 노드간 관계가 정의되고 하는지는 Neo4j나 다른 GraphDB의 아키텍처를 더 뜯어 봐야 할것 같습니다. 지금은 MongoDB에 집중하고 있기도 해서 언제 여유가 되고 기회가 된다면 공부해보면 재밌을것 같습니다. 기말 공부가 끝나면 MongoDB에 대한 포스팅을 마저하고, MongoDB DBA 자격시험을 좀 준비 해야겠네요.
참고 자료
도서: Neo4j로 시작하는 그래프 데이터베이스 2/e
안녕하세요.
우연히 들어와 좋은 식견과 지식 배우고 갑니다.
혹시 오른쪽 커뮤니티(open source DB) 비밀번호를 알 수 있을까요??
mysql 의 기본 포트 번호입니다. ^^
너무 재미있는 내용이었습니다. 요새 국비지원듣는데 이런 자료 너무 좋네요 ㅠㅠ